I conducted my Master’s thesis at the Computer Graphics Laboratory of the Swiss Federal Institute of Technology in Zürich (ETHZ) under the guidance of Prof. Dr. Barbara Solenthaler, Dr. Baran Gözcü, and Till Schnabel from ETHZ, as well as Prof. Dr. Wenzel Jakob from the Swiss Federal Institute of Technology in Lausanne (EPFL).
During that time, I worked on enhancing an infant face morphable model, focusing on improving low-res textures from 3D baby face models to create high-res, lifelike images using texture super-resolution and photometric albedo fitting.
As I used confidential patient data, I can show results of this project on demand only but cannot distribute them or publish them on this website for now.
Keypoints
- Deep learning
- Neural rendering
- Image processing
- Academic research
- Paper-ready writing
- GANs
- Diffusion models
- PyTorch (Python)
TL;DR
My thesis was part of a broader initiative to create high-fidelity 3D models of infant faces using medical datasets to aid in the reconstruction of personalised morphologies for infants with craniofacial malformations. These models aim to improve diagnostics, surgical planning, and postoperative evaluations. Current techniques struggle with limited data and incomplete scans due to infants’ spontaneous expressions and movements.
I focused on upsampling textures combining low-resolution and high-resolution areas to achieve uniform high resolution. I adapted the pix2pixHD pipeline for super-resolution inpainting, creating a triple discriminator architecture with differentiable rendering to handle both texture and image space losses. To address lighting inconsistencies in outputs, I explored relighting techniques and photometric optimisation using the FLAME morphable model. This included optimising parameters across multiple images for accurate lighting and albedo.
Problem statement
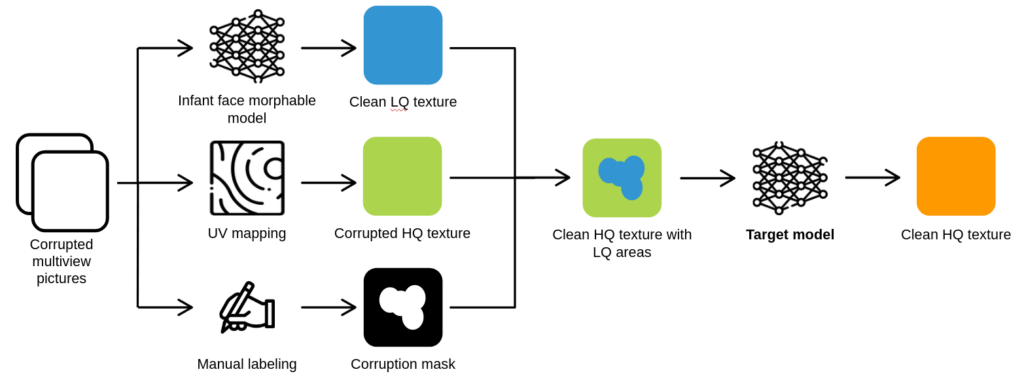
My work was part of a larger initiative to develop a 3D morphable model of infant faces using facial scans. This model leverages two autoencoders to capture shape and appearance from 3D positional and RGB colour data, though it currently produces low-resolution textures.
High resolution textures can be derived from multi-view images but contain artifacts like pacifiers or hands. The morphable model generates artifact-free lower resolution textures. By merging these, we can create high-resolution textures with low-resolution areas filling in the gaps caused by corrupted data.
The objective of my project was to upsample this combined texture to achieve a uniform high resolution, seamlessly integrating the morphable model-generated areas with the original high-resolution textures. Explicitely, the goal was thus to establish a super-resolution pipeline that enhances low-resolution areas of infant face textures with high-resolution details, within a high-resolution texture
Texture super-resolution pipeline
The first part of my project focused on developing the super-resolution inpainting pipeline.
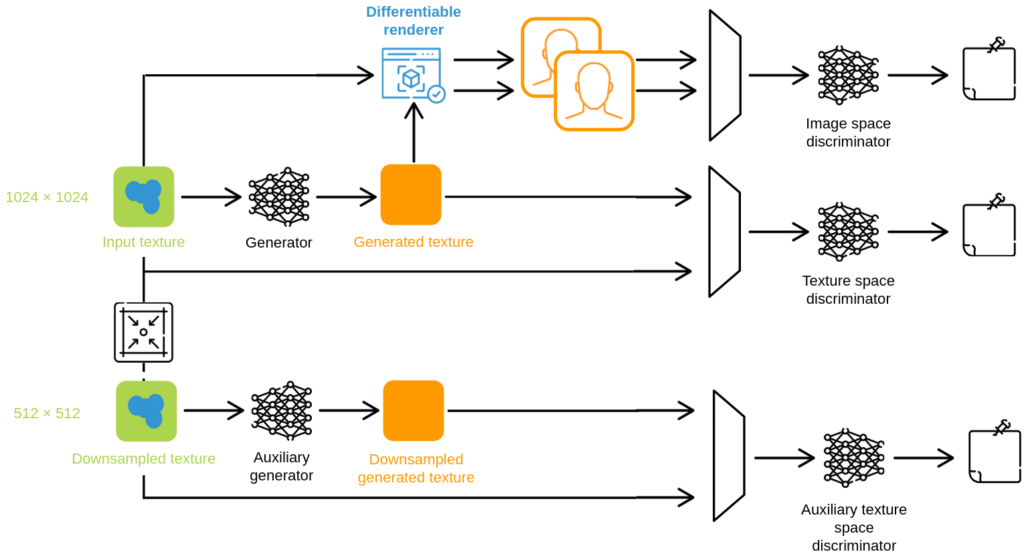
I began by adapting the pix2pixHD pipeline for this specific task. Initially, I experimented with the generation strategy of the corruption masks used for training. I then modified the pipeline’s architecture by incorporating differentiable rendering. This enhancement allowed the model to train with losses computed in image space rather than texture space, particularly perceptual losses.
On top of the double discriminator architecture of pix2pixHD, I implemented a triple discriminator architecture, with the two original discriminators operating in texture space and a new one operating in image space.
Photometric albedo fitting pipeline
Early in my experiments, I encountered challenges with how pix2pixHD handled lighting in the outputs. The inconsistent treatment of specular highlights led to noticeable differences between areas derived from the ground-truth high-resolution textures and those upsampled by our model.
To address this, I explored relighting techniques to enhance lighting diversity within our dataset, alongside refining our main pix2pixHD pipeline. Extracting lighting data directly from textures is challenging. I thus investigated projects capable of either relighting or removing lighting from multi-view images from which the textures are extracted, preferably with joint processing to ensure consistency across views.
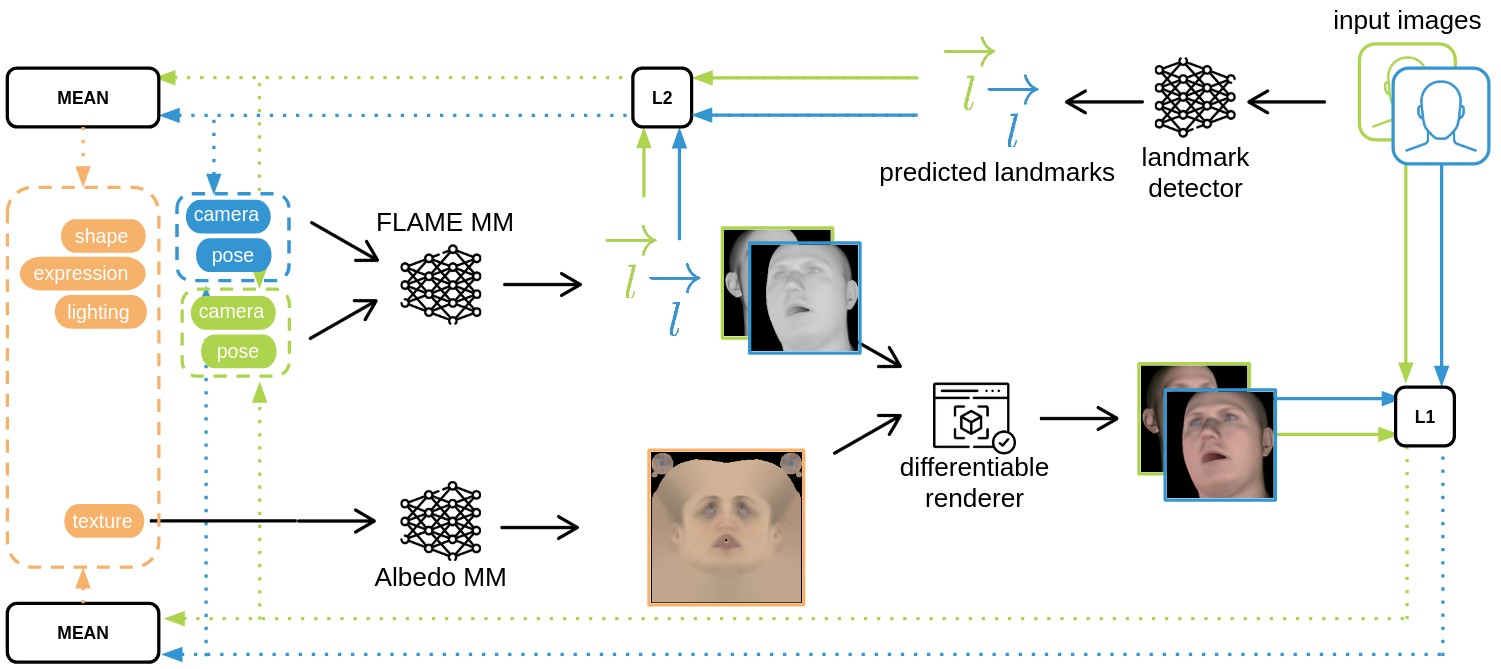
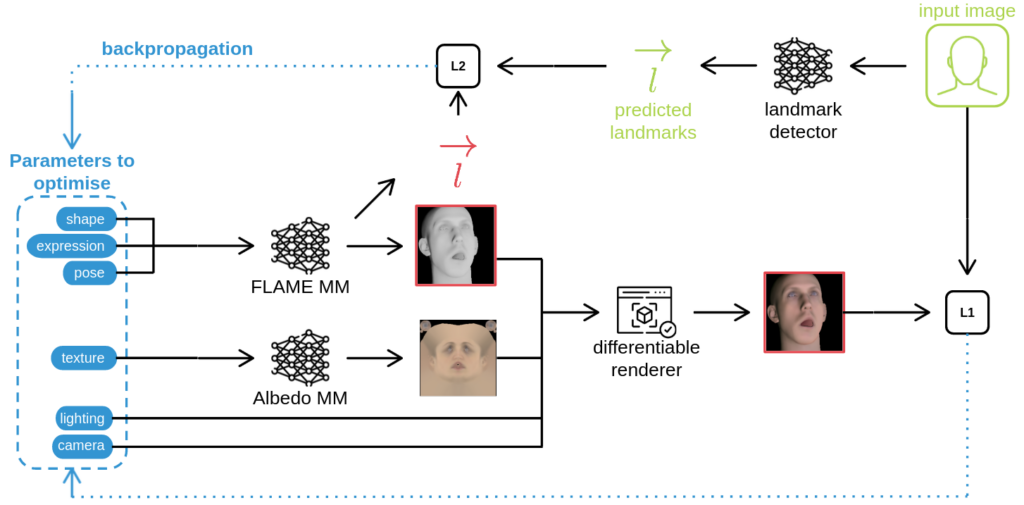
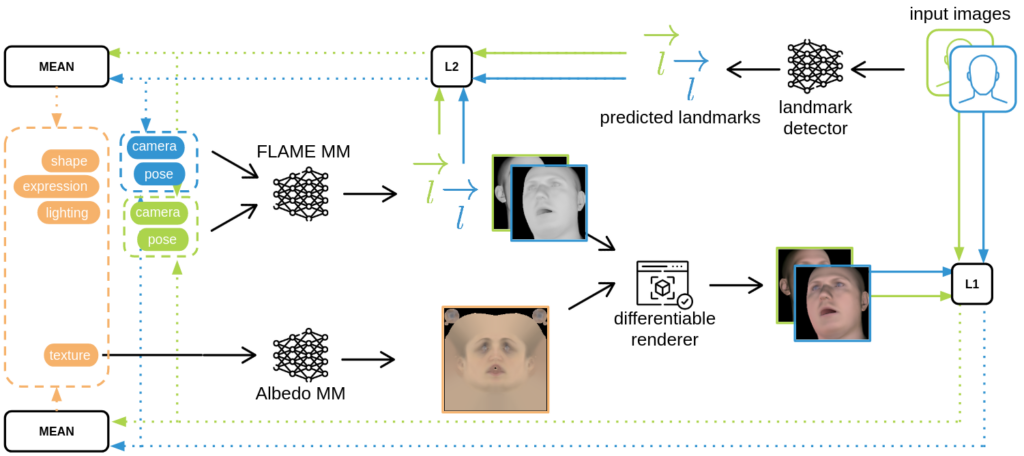
I decided to use a photometric optimisation technique relying on the FLAME morphable model, along with the FLAME albedo morphable model. It optimises simultaneously the FLAME parameters, albedo model parameters, and rendering parameters, all guided by an input image. The goal is to generate a textured and illuminated FLAME mesh that accurately reflects the input image, including its lighting and albedo. The initial pipeline looks as follows:
The main enhancement I implemented in this pipeline is the ability to optimise certain parameters jointly across multiple input images. I identified parameters that are suitable for joint optimisation across all multi-view images (shape, expression, texture, and lighting) and those that require individual optimisation for each image (pose, camera parameters) and updated the pipeline as shown below:
I also addressed the challenge of accommodating dark skin albedos within the pipeline by adapting the optimised lighting, face segmentation, and preprocessing steps. This resulted in improved albedo estimation for dark-skinned patients.